
Asynchronous Advantage Actor Critic Agents (2020)
Content
In the growing field of reinforcement learning, so-called “Actor- Critic” models are being used with great success. In this work, we implemented a type of this model called Asynchronous Advantage Actor Critic (A3C). A3C has several training instances running in parallel but still enables sharing a network architecture, weights and weight updates across agents. We implemented A3C as well as a preprocessing and evaluation pipeline in the PyTorch framework. The algorithm in our work is applied in a novel environment, developed by the AI department at Radboud University. During training and test time, the agent is provided with high-level sensory inputs only. In addition to the implementation details and our results, we provided some insight into the biological plausibility of the A3C algorithm.
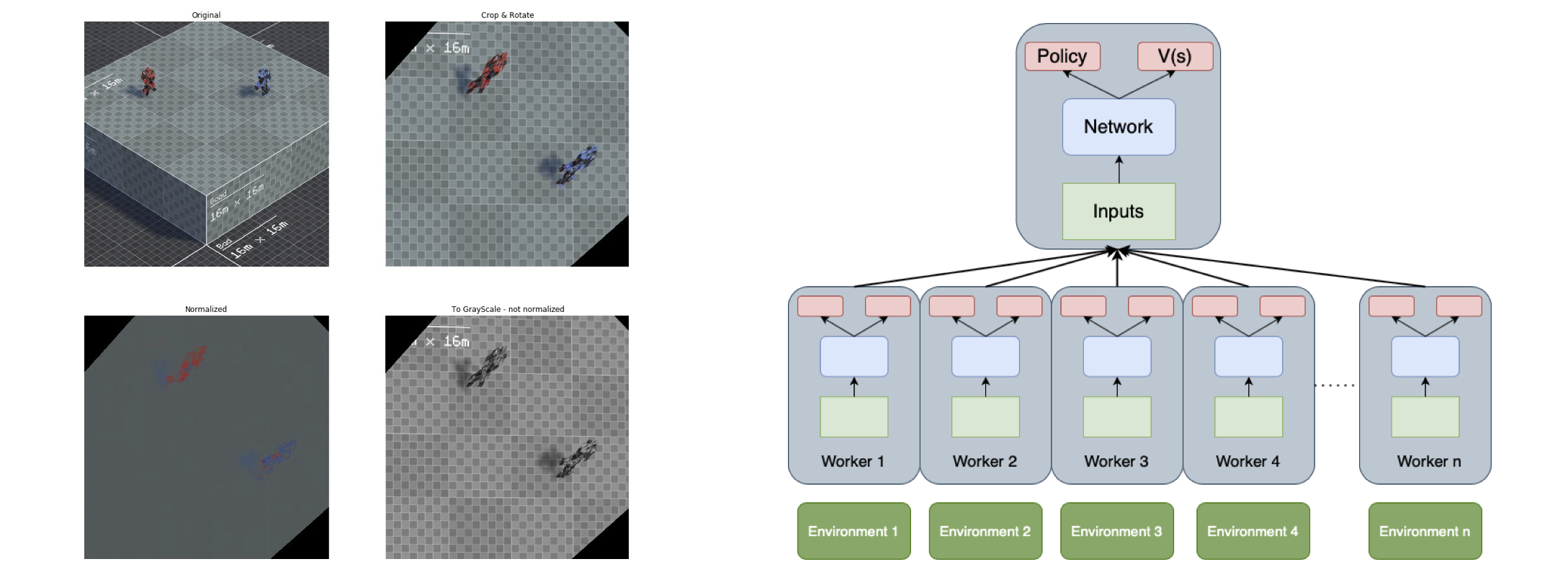
The image on the left shows the preprocessing pipeline. The right figrues disaplys the A3C model architecture. We found that our implementation of the algorithm effectively learned OpenAI Gym’s CartPole on parameter inputs. We implemented an image preprocessing pipeline and an autoencoder structure. However, the complexity of the pixel-inputs was too high to be effectively learned by our implementation with convolutional layers.
Main reference: Asynchronous Methods for Deep Reinforcement Learning