Multi Source Domain Adaptation (2018|19)
Introduction
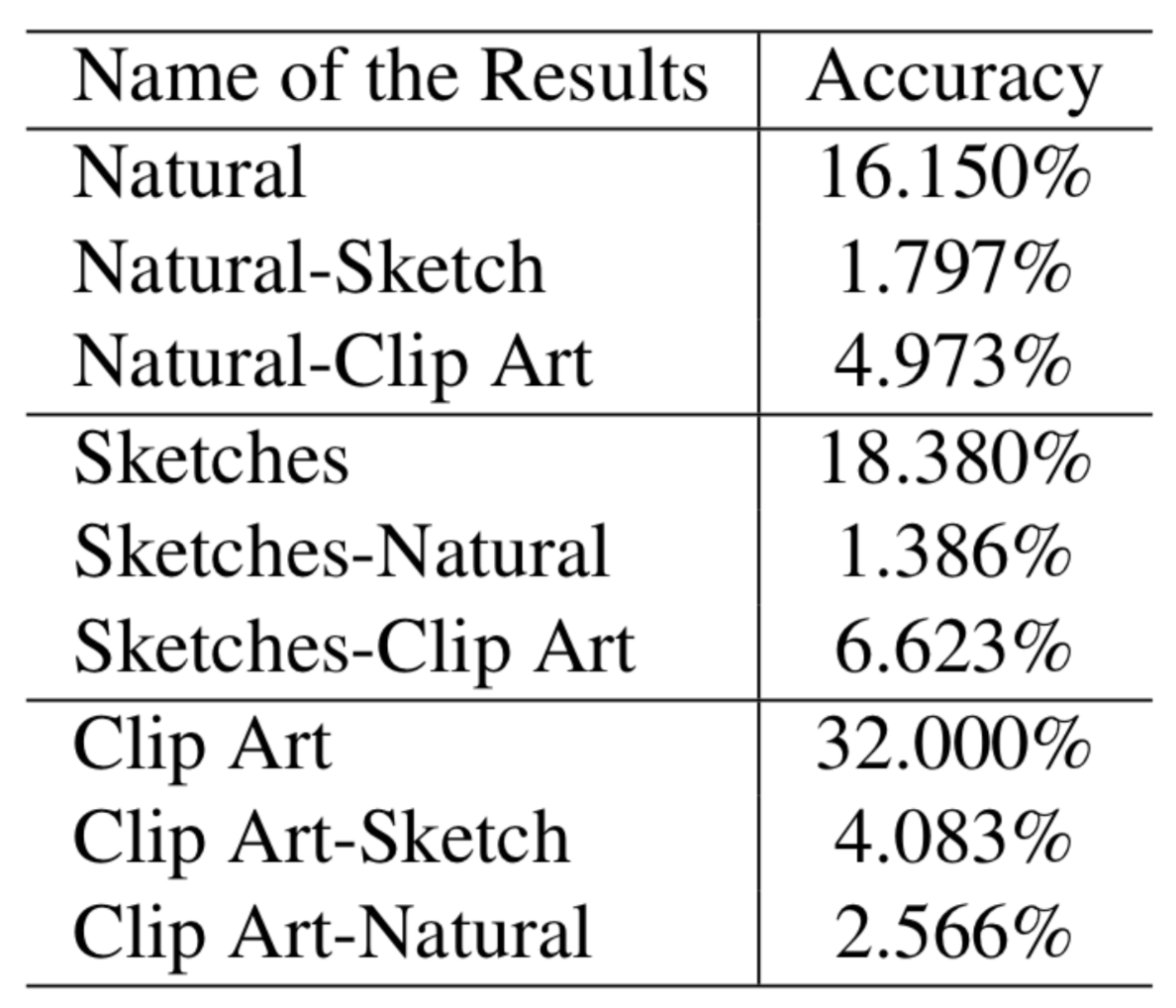
Humans are able to recognize scenes independently of the modality they perceive it in. In this paper, it is tested if scene specific features extracted from natural images are reusable for classifying clip art and sketches. Further, the ability of networks to hold multiple representations simultaneously is examined. To study this problem a pretrained convolutional neural network is used. Further, a randomly initialized classifier is added and retrained. The representations of clip art achieve the highest results, followed by sketches. Natural image performance remains notably below prior results. The experiment suggests that the overall transferability of learned features is not only limited by the distance but also by the diversity of the input distribution. Moreover, a multimodal representation is shown to be feasible but only poorly. Further research is needed to explain the obtained outcomes and to explain why they deviate from previous expectations.
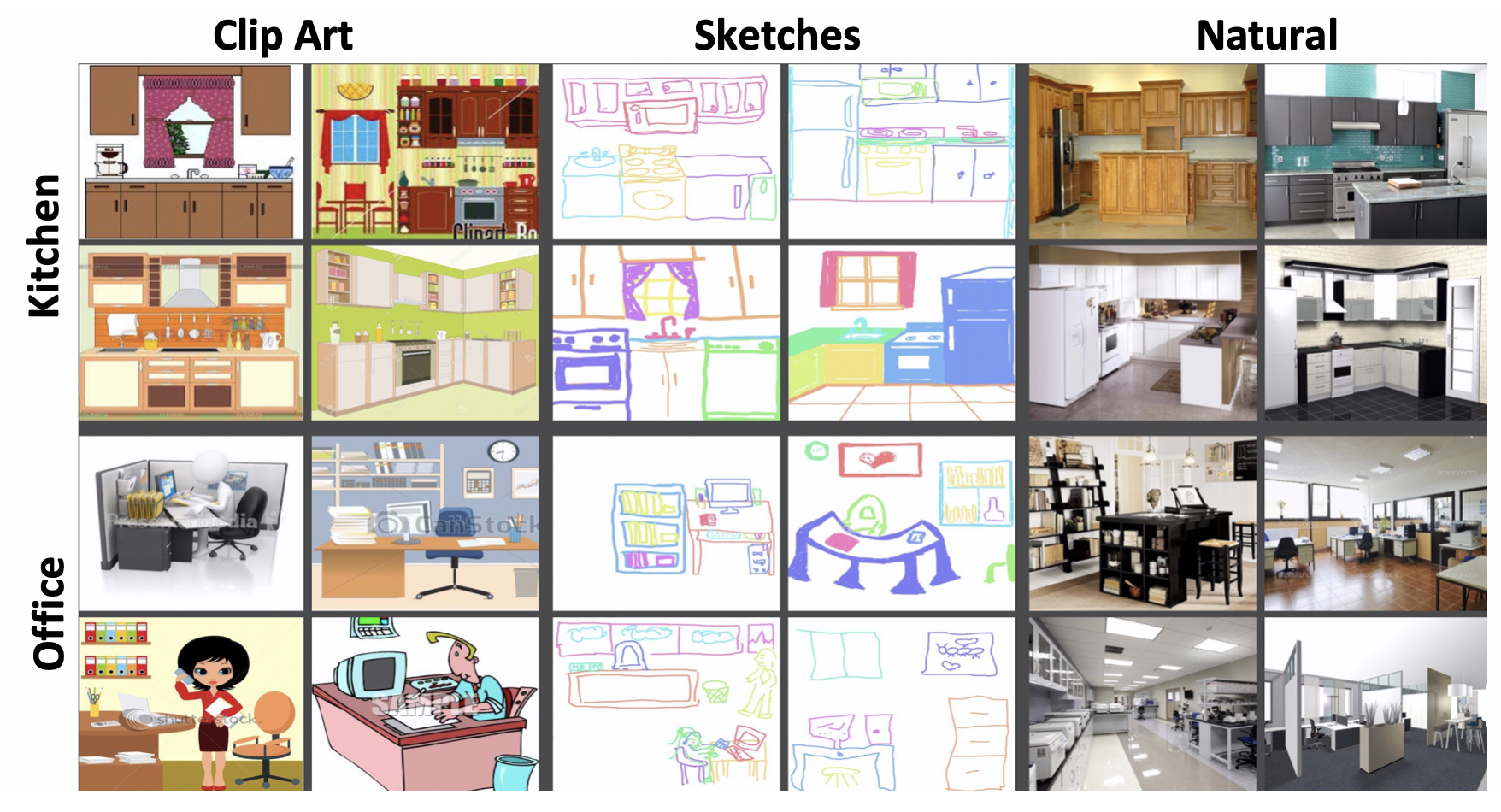
The figure shows a kitchen and an office (concepts) acrossdifferent modalities (clip art, sketches and natural images)..
Can you recognize scenes across different styles?
The input variables consist of natural images from theScene205 dataset collected and curated by B. Zhou et al.(2014). An exhaustive list of the classes can be found inappendix 1. The set contains around 2.5 million images from205 scene categories. The compressed file contains resized 256*256 images, split into a train set and a validation setof Places 205 with a size of 126GB. Due to computationallimitations the number of pictures is reduced to around 80pictures per object, so that 16,400 pictures remain. Thesketch images consist of 14,830 training and 2,050 valida-tion sketches collected through Amazon Mechanical Turk,whereby different colors indicate different objects. The clipart data includes 11,372 training and 1,954 validation clipart images downloaded from search engines. Sketches andclip art were assembled by Aytar et al. (2018).
VGG16 Architecture
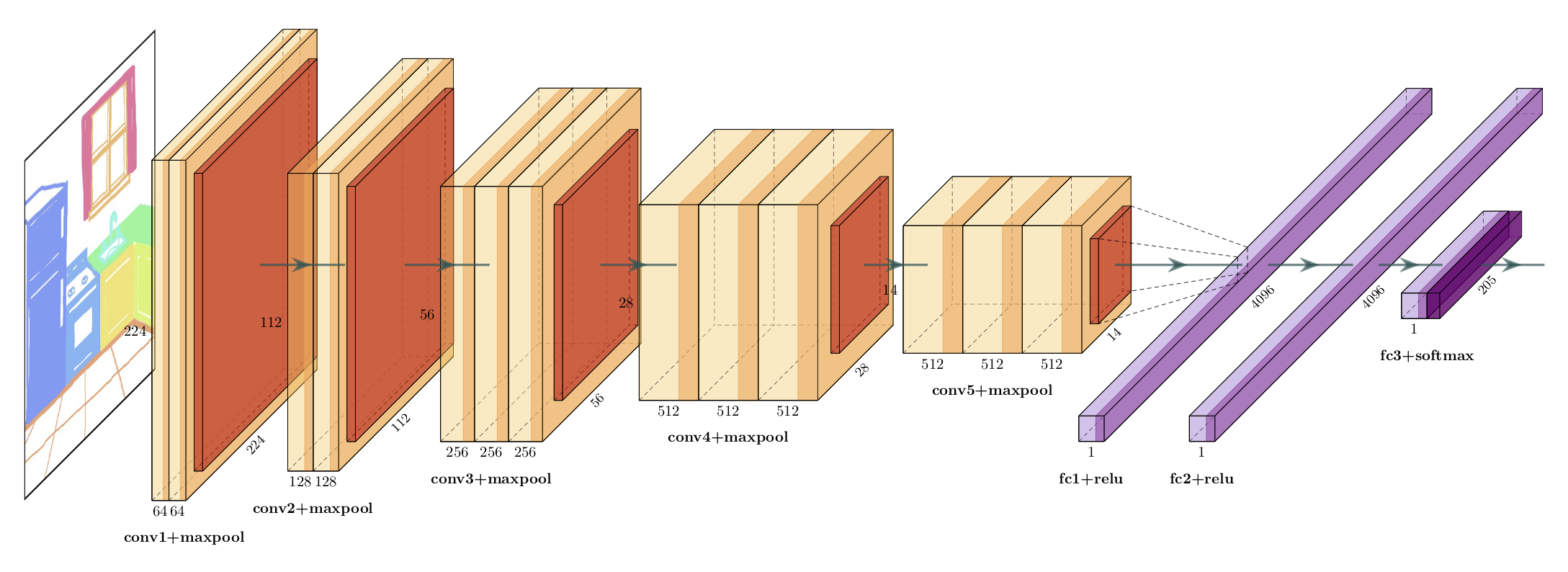
The picture on the left shows the input of the network, consisting of an RGB image. Thenetwork consists of packages of convolution layers followed by an activation function, namely a rectified linear unit (ReLU)and finally a maxpooling layer. Those packages are repeated and followed by three fully connected layers. Convolution andmaxpooling layers, shown in orange and red are frozen during training. The fully connected layers (here abbreviated with fc)make up the classifier, shown in purple. Everything prior to the classifier is frozen and only the classifier is trained.
Mapping Mechanisms
To assess the research questions in an experimental man-ner, a pretrained network is used instead of training a networkfrom scratch. The image classification architecture chosen isthe VGG16 assembled by Simonyan and Zisserman (2014).It is well established and has a feedforward architecture. Thisway the network is well equipped to map the input, the im-ages, to the output, the labels. The VGG16 architecture isretained, consisting of 14.714.688 million parameters par-tioned over 13 convolutional layers. The 5 maxpooling lay-ers and the ReLU which is applied after every convolutionallayer, do not add further parameters.
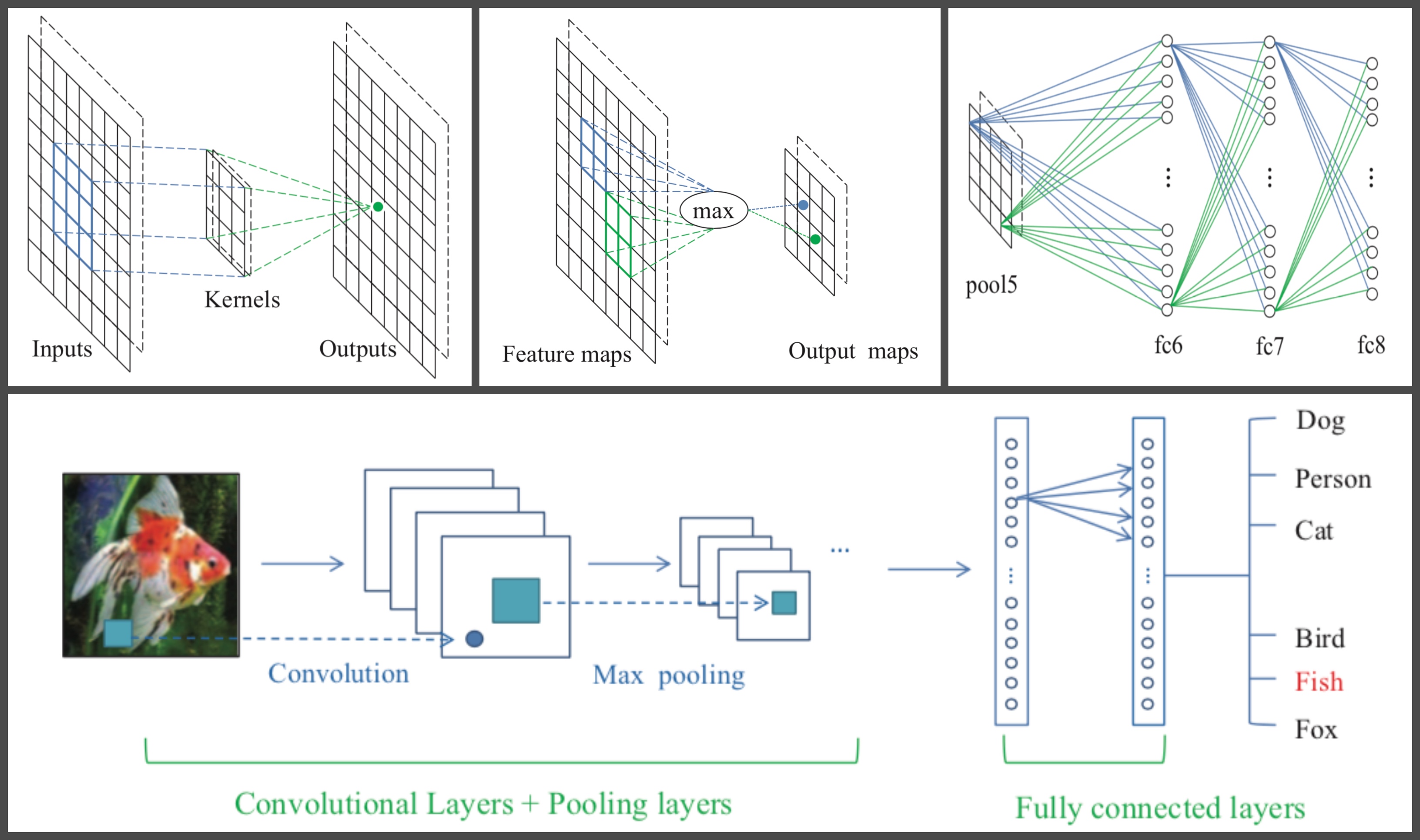
Convolutions and ReLU are the core buildingblocks in ConvNets. Convolutional networks convert an in-put via a kernel function that slides over the input into anoutput called feature map. It is used as an edgedetector or filter and works by convoluting a kernel and aninput. The filter value are not static but learned during the process. Compared to fully connected layers convolutionallayers have sparse weights, this way it is unnecessary for every output unit to interact with every input unit. The kernels are smaller than the input, this way they reduce the amount of parameters. The next stage in a ConvNet consists of a nonlinear activa-tion function. During this step the obtained feature maps are passed through a non-linearity such as a rectified linear unit(ReLU). ReLU is the most popular non-linear function con-sisting of a rectifierf(z)=max(z,0). ReLu was first used by Krizhevsky et al. (2012), they showed that it allows faster training of a deep supervised network without unsupervised pre-training.
Pooling is a way of sub-sampling. Average pooling for example replaces the output at a certain location with a summary of nearby inputs. In the network a max-pooling operation is applied which returns the maximum value for a set of neighboring neurons. This form of subsampling yields the advantage of progressively reducing the size of the representation.
Conclusion
The representations stored within the pretrained ConvNet are reusable for classifying clipart and sketches. All models performed best on the domain they were trained on. The representations of clip art achieve the high- est results, followed by sketches. Natural image performance remains notably below prior results.